Adquisición de Métricas
¿Que es CAdvisor?
cAdvisor (abreviatura de c ontainer Advisor ) analiza y expone el uso de recursos y los datos de rendimiento de los contenedores en ejecución. Dentro de sus principales características podemos destacar:
- cAdvisor es un recopilador de uso de recursos de contenedores de código abierto.
- Soporte nativo para contenedores Docker y solo admite otros tipos de contenedores.
- cAdvisor funciona por nodo. Detecta automáticamente todos los contenedores en el nodo dado y recopila estadísticas de uso de la CPU, la memoria, el sistema de archivos y la red.
- Soporte para ejecutar de forma independiente fuera de Docker o cualquier otro contenedor.
- Proporciona el uso general de la máquina analizando el contenedor 'raíz' en la máquina.
- Admite la exportación de estadísticas a varios complementos de almacenamiento, por ejemplo, Elasticsearch, InfluxDB, etc.
- Las métricas se pueden ver en la interfaz de usuario web, /containers que exporta información en vivo sobre todos los contenedores en la máquina.
- Expone estadísticas sin procesar y procesadas a través de una API REST remota versionada.
Limitaciones
- Recopila la utilización de recursos básicos, es decir, no podríamos obtener el rendimiento real de las aplicaciones de contenedor, por ejemplo, x% de utilización de CPU
- No ofrece capacidades de análisis, tendencias o almacenamiento a largo plazo.
¿Como se observa el panel de administracion para monitorear las pruebas de rendimiento?
Una vez desplegado el contenedor, podemos acceder via web a traves de https://127.0.0.1:8080 y se abrirá una interfaz bastante sencilla e intuitiva, la cual nos va a mostrar los recursos del sistema y el listado de contendores que tenemos desplegados.
¿Que es Django Debug?
Django Debug como su nombre lo indica, es una herramienta que permite vigilar el rendimiento de una aplicacion desarrollada en Django.Nos proporciona entre otras cosas: información de consultas de base de datos, templates usadas y tiempos de carga.
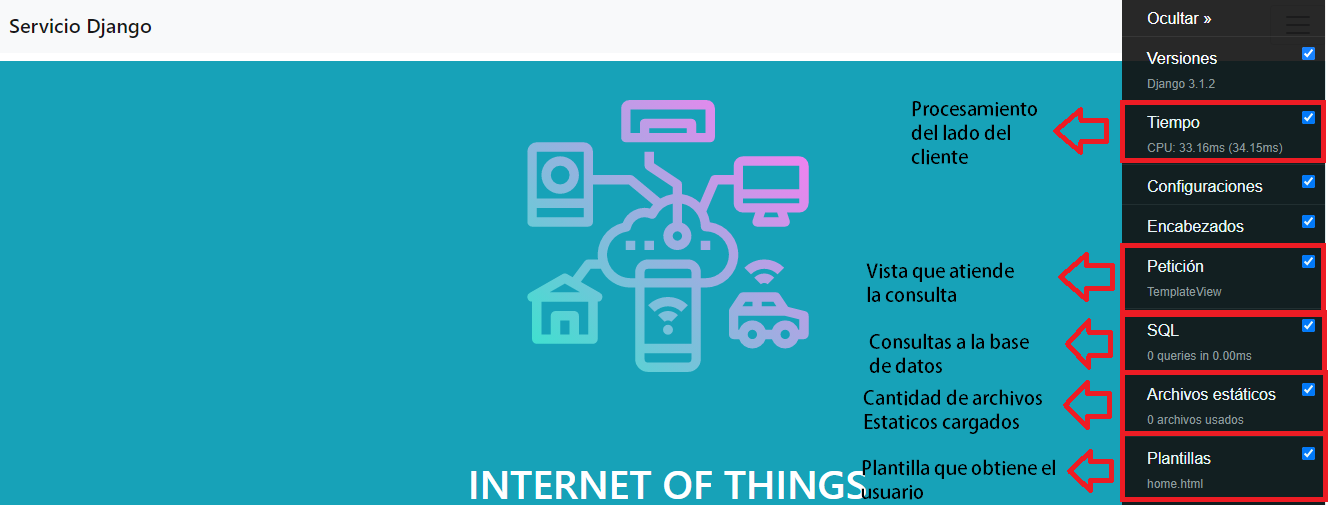
¿Que preguntas nos ayuda a responder?
- ¿Cuántas consultas SQL se ejecutaron?
- ¿Cuál fue el tiempo acumulado en la base de datos?
- ¿Qué consultas individuales se ejecutaron y cuánto tiempo tomó cada una?
- ¿Qué código genera cada consulta?
- ¿Qué plantillas se usaron para renderizar la página?
- ¿Cómo afecta el caché al rendimiento?
Consultas para un Loguin
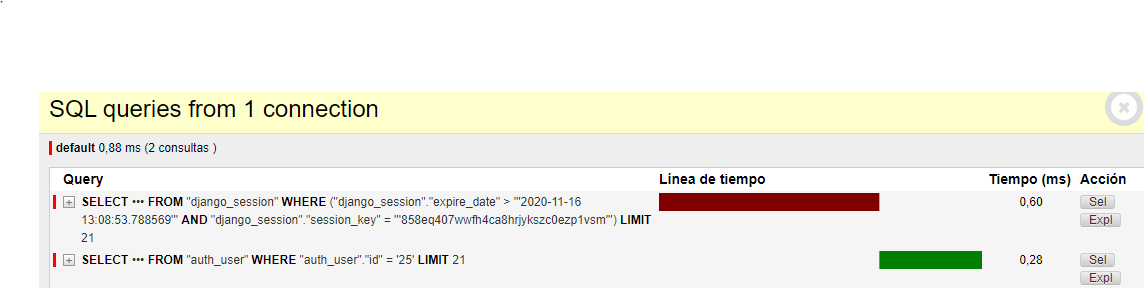
Consultas para registrar un dato
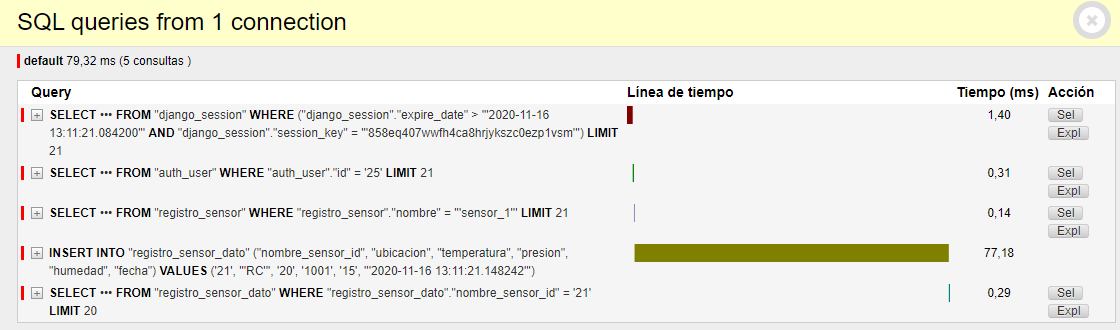
Consulta para visualizar datos

¿ Donde optimizar la aplicacion web ?
En casi todas las aplicaciones web dinámicas el cuello de botella siempre es la base de datos ya que con frecuencia se necesita acceder a la información de los discos y realiza cálculos costosos en la memoria para consultas complejas.
Minimizar el número de consultas como el tiempo que necesitan para ejecutarse es una forma segura de acelerar la aplicación.
Minimizar el número de consultas como el tiempo que necesitan para ejecutarse es una forma segura de acelerar la aplicación.
Para lograr estos objetivos se pueden aplicar muchas modificaciones y optimizaciones sobre las consultas a las bases de datos. Para mas detalles consulte la siguiente url.
Optimizacion de aplicaciones Django
¿Qué es Telegraf?
Telegraf es un agente de servidor basado en complementos para recopilar y enviar métricas y eventos de bases de datos, sistemas y sensores de IoT.
Es una herramienta escrita en Go que requiere una huella de memoria minima y se compila en un único binario sin dependencias externas.
Es una herramienta escrita en Go que requiere una huella de memoria minima y se compila en un único binario sin dependencias externas.
¿Por qué utilizar Telegraf?
Recopila y envía todo tipo de datos:
- Base de datos: conéctese a fuentes de datos como MongoDB, MySQL, Redis y otras para recopilar y enviar métricas.
- Sistemas: recopile métricas de su pila moderna de plataformas, contenedores y orquestadores en la nube.
- Sensores de IoT: recopile datos de estado críticos (niveles de presión, niveles de temperatura, etc.) de los sensores y dispositivos de IoT.
Agente
Telegraf puede recopilar métricas de una amplia gama de entradas y escribirlas en una amplia gama de salidas. Está impulsado por complementos tanto para la recopilación como para la salida de datos, por lo que se puede ampliar fácilmente. Está escrito en Go, lo que significa que es un binario compilado e independiente que se puede ejecutar en cualquier sistema sin necesidad de dependencias externas, sin necesidad de npm, pip, gem u otras herramientas de administración de paquetes.
Cobertura
con más de 200 complementos, es fácil comenzar a recopilar métricas de los diferentes puntos finales. Ademas, la facilidad del desarrollo de complementos significa que se pueden crear diferentes complementos que se adapten a las necesidades particulares de monitoreo.
Flexible
La arquitectura del complemento Telegraf admite procesos propios de la estructura de servicios implementada y no obliga a cambiar los diferentes flujos de trabajo para usar esta tecnología. Simplemente se adapta a la arquitectura en lugar de al revés. La flexibilidad de Telegraf hace que sea una decisión fácil de implementar.
Telegraf en nuestro proyecto
A continuacion se presenta el archivo de configuracion Telegraf de forma resumida, con sus principales configuraciones y plugins:
# Configuration for telegraf agent
[agent]
## Default data collection interval for all inputs
interval = "10s"
## Rounds collection interval to 'interval'
## ie, if interval="10s" then always collect on :00, :10, :20, etc.
round_interval = true
## Telegraf will send metrics to outputs in batches of at most
## metric_batch_size metrics.
## This controls the size of writes that Telegraf sends to output plugins.
metric_batch_size = 1000
## Maximum number of unwritten metrics per output. Increasing this value
## allows for longer periods of output downtime without dropping metrics at the
## cost of higher maximum memory usage.
metric_buffer_limit = 10000
## Collection jitter is used to jitter the collection by a random amount.
## Each plugin will sleep for a random time within jitter before collecting.
## This can be used to avoid many plugins querying things like sysfs at the
## same time, which can have a measurable effect on the system.
collection_jitter = "0s"
## Default flushing interval for all outputs. Maximum flush_interval will be
## flush_interval + flush_jitter
flush_interval = "10s"
## Jitter the flush interval by a random amount. This is primarily to avoid
## large write spikes for users running a large number of telegraf instances.
## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15s
flush_jitter = "0s"
## By default or when set to "0s", precision will be set to the same
## timestamp order as the collection interval, with the maximum being 1s.
## ie, when interval = "10s", precision will be "1s"
## when interval = "250ms", precision will be "1ms"
## Precision will NOT be used for service inputs. It is up to each individual
## service input to set the timestamp at the appropriate precision.
## Valid time units are "ns", "us" (or "µs"), "ms", "s".
precision = ""
## Log at debug level.
# debug = false
## Log only error level messages.
# quiet = false
## Log target controls the destination for logs and can be one of "file",
## "stderr" or, on Windows, "eventlog". When set to "file", the output file
## is determined by the "logfile" setting.
# logtarget = "file"
## Name of the file to be logged to when using the "file" logtarget. If set to
## the empty string then logs are written to stderr.
# logfile = ""
## Override default hostname, if empty use os.Hostname()
hostname = ""
## If set to true, do no set the "host" tag in the telegraf agent.
omit_hostname = false
###############################################################################
# OUTPUT PLUGINS #
###############################################################################
# Configuration for sending metrics to InfluxDB
[[outputs.influxdb]]
## The full HTTP or UDP URL for your InfluxDB instance.
urls = ["http://172.20.0.4:8086"]
## The target database for metrics; will be created as needed.
## For UDP url endpoint database needs to be configured on server side.
# database = "telegraf"
database = "telegraf"
## If true, no CREATE DATABASE queries will be sent. Set to true when using
## Telegraf with a user without permissions to create databases or when the
## database already exists.
# skip_database_creation = false
skip_database_creation = false
## Name of existing retention policy to write to. Empty string writes to
## the default retention policy. Only takes effect when using HTTP.
# retention_policy = ""
retention_policy = ""
## The value of this tag will be used to determine the retention policy. If this
## tag is not set the 'retention_policy' option is used as the default.
# retention_policy_tag = ""
retention_policy_tag = ""
## Timeout for HTTP messages.
# timeout = "5s"
timeout = "5s"
## HTTP Basic Auth
# username = "telegraf"
# password = "metricsmetricsmetricsmetrics"
username = "admin"
password = "admin"
###############################################################################
# INPUT PLUGINS #
###############################################################################
# Read metrics about cpu usage
[[inputs.cpu]]
## Whether to report per-cpu stats or not
percpu = true
## Whether to report total system cpu stats or not
totalcpu = true
## If true, collect raw CPU time metrics.
collect_cpu_time = false
## If true, compute and report the sum of all non-idle CPU states.
report_active = false
# Read metrics about disk usage by mount point
[[inputs.disk]]
## By default stats will be gathered for all mount points.
## Set mount_points will restrict the stats to only the specified mount points.
# mount_points = ["/"]
## Ignore mount points by filesystem type.
ignore_fs = ["tmpfs", "devtmpfs", "devfs", "iso9660", "overlay", "aufs", "squashfs"]
# Read metrics about disk IO by device
[[inputs.diskio]]
## By default, telegraf will gather stats for all devices including
## disk partitions.
## Setting devices will restrict the stats to the specified devices.
# devices = ["sda", "sdb", "vd*"]
## Uncomment the following line if you need disk serial numbers.
# skip_serial_number = false
#
## On systems which support it, device metadata can be added in the form of
## tags.
## Currently only Linux is supported via udev properties. You can view
## available properties for a device by running:
## 'udevadm info -q property -n /dev/sda'
## Note: Most, but not all, udev properties can be accessed this way. Properties
## that are currently inaccessible include DEVTYPE, DEVNAME, and DEVPATH.
# device_tags = ["ID_FS_TYPE", "ID_FS_USAGE"]
#
## Using the same metadata source as device_tags, you can also customize the
## name of the device via templates.
## The 'name_templates' parameter is a list of templates to try and apply to
## the device. The template may contain variables in the form of '$PROPERTY' or
## '${PROPERTY}'. The first template which does not contain any variables not
## present for the device is used as the device name tag.
## The typical use case is for LVM volumes, to get the VG/LV name instead of
## the near-meaningless DM-0 name.
# name_templates = ["$ID_FS_LABEL","$DM_VG_NAME/$DM_LV_NAME"]
# Get kernel statistics from /proc/stat
[[inputs.kernel]]
# no configuration
# Read metrics about memory usage
[[inputs.mem]]
# no configuration
# Get the number of processes and group them by status
[[inputs.processes]]
# no configuration
# Read metrics about swap memory usage
[[inputs.swap]]
# no configuration
# Read metrics about system load & uptime
[[inputs.system]]
## Uncomment to remove deprecated metrics.
# fielddrop = ["uptime_format"]
###############################################################################
# SERVICE INPUT PLUGINS #
###############################################################################
# # Read metrics from one or many postgresql servers
[[inputs.postgresql]]
address= "host=172.20.0.8 user=postgres password=postgres dbname=postgres"
Para entender las configuraciones es necesario tomar el archivo Telegraf base y analizar cada comentario y variable dentro de las pequeñas secciones separadas por [[(plugin particular)]]. Es destacable el orden que tiene el archivo y la forma en la cual esta documentado, ya que resulta bastante sencillo adaptar cada plugin a las necesidades particulares y arquitectura de red presente. El primer paso consisten en modificar la seccion [agents],ya que sin importan el plugin de entrada o de salida que se utilice, el agente telegraf se basara en dichas configuraciones. Luego dependiendo el tipo de servicio que se desee monitorear se configuran los INPUT PLUGINS y SERVICE INPUT PLUGINS. Para finalmente, configurar algunos parametros asociados a la base de datos a la cual se conectara telegraf para guardar las metricas adquiridas. Estas configuraciones estan en OUTPUT PLUGINS