Generación de tráfico
¿Qué es Locust?
Locust es una herramienta de prueba de carga de usuario distribuida y fácil de usar. Está diseñado para sitios web de prueba de carga (u otros sistemas) y para determinar cuántos usuarios simultáneos puede manejar un sistema.
La idea es que, durante una prueba, un "enjambre de langostas" ataque el sitio web. El comportamiento de cada langosta (o usuario de prueba, si lo desea) se lo puede definir y el proceso de enjambre se supervisa desde una interfaz de usuario web en tiempo real. Esto ayudará a luchar contra las pruebas e identificar los cuellos de botella en el código antes de permitir la entrada a usuarios reales.
Como poner en marcha rápidamente
Requerimientos previos
A continuación, se adjuntan un conjunto de requisitos para inicializar Locust. Las versiones no son requerimientos excluyentes en todos los casos. Se recomienda respetar en cualquier caso la versión del sistema operativo y una version de Python 3.x.
1 - Sistema operativo Linux. Versión: 18.04.3
2- Python instalado. Versión: 3.6.8
3- Docker instalado. Versión: 19.3.11
Procedimiento
1- Cree una carpeta de trabajo donde levantar Locust.
2- Dentro del directorio, crear un archivo de configuración Locust denominado "locustfile.py".
3- Genere la configuración de las pruebas de performance en dicho archivo considerando la documentación oficial.
4- Ejecute el siguiente comando docker con una terminal dentro de la carpeta de trabajo.
docker run -p 8089:8089 -v $PWD:/mnt/locust locustio/locust -f /mnt/locust/locustfile.py
¿Cómo se interpreta el comando? En primer lugar, "docker run" levantará un contenedor con la imagen locustio/locust. Además, Tener en cuenta que las especificaciones "-p (puert.Host:puert.Cont)" expondrán los puertos 8089 del contenedor, en los puertos del host 8089. Luego, "-v (direct.Host):(direct.Cont)" determina que se realizará una copia del directorio del host dentro de una ubicación en el contenedor, esto genera que las modificaciones en tiempo real de los archivos en el directorio del host, cambien directamente los archivos dentro del contenedor. De esta forma $PWD, está indicando la ubicación actual de trabajo que se copiará dentro de la dirección /mnt/locust del contenedor. La fracción del comando que realiza dicha tarea es "-v $PWD:/mnt/locust". Por último, como el archivo "locustfile.py" estaba en la carpeta de trabajo, se habrá copiado dentro del contenedor en la dirección /mnt/locust, por lo que habrá que especificar que el archivo de pruebas de performance para Locust se encuentra en "/mnt/locust/locustfile.py". Esto se realiza con la última parte del comando "-f /mnt/locust/locustfile.py".
Comenzando con las pruebas
Prueba básica: Consulta a servidor
Para comenzar a realizar testing de tráfico mediante el uso de Locust, tiene sentido comenzar por una prueba bien básica como la se comentará a continuación. En este apartado, mediante el código inicial "basicTest_locust.py" que se encuentra en la carpeta "desarrollo/Generacion de trafico" de este mismo proyecto, se realizan consultas al servidor de interés con la finalidad de garantizar nuestra llegada hasta la dirección indicada tanto mediante la visualización desde la página de Locust como del terminal del servidor.
from locust import HttpUser, task, between
class WebsiteUser(HttpUser):
wait_time = between(1,2)
@task
def index(self):
self.client.get("/")
En el código presentado se puede observar la importación de la clase "HttpUser" para que los usuarios puedan realizar solicitudes Http, además se importa "task" para asignar las distintas tareas a realizar y finalmente "between()" que definirá cada cuanto tiempo se ejecutarán las distintas tareas "@task".
Luego se crea la clase "WebsiteUser", en donde se define la tarea "index"que realizará el usuario designado. En este caso lo único que será es realizar un "get" hacia la página inicial, que en este caso sería hacia nuestro servidor al cual se llega mediante la asignación de la dirección ip desde la página o servidor de Locust.
Por último, para poder correr este script y mediante un terminal ubicado en la misma carpeta que contiene al archivo "basicTest_locust.py" se debe de ejecutar el siguiente comando:
docker run -p 8089:8089 -v $PWD:/mnt/locust locustio/locust -f /mnt/locust/basicTest_locust.py
Una vez que se inicializa Locust y queda estable. Se debe acceder mediante el navegador web a la dirección: 'http://127.0.0.1:8089'
Locust en nuestro proyecto
Locust como servicio generador de trafico, se ejecuta en una estructura dockerizada. Como se puede ver a continuacion, tiene dedicada una porcion de codigo en el archivo docker-compose.yml:
locust:
build: ScriptLocust
command: -f /mnt/locust/Test_locust_regUser_08-11-2020.py
volumes:
- ./ScriptLocust:/mnt/locust
ports:
- "8089:8089"
links:
- web:web
networks:
red_servicios:
ipv4_address: 172.21.0.3
container_name: Locust_SQlite
Lo mas importante es que una vez construido el contenedor y montada la carpeta ScriptLocust dentro del mismo en la direccion mnt/locust, se ejecuta command, lo que indica que debe correr el servicio utilizando como script Test_locust_regUser_08-11-2020.py
Script para pruebas de performance
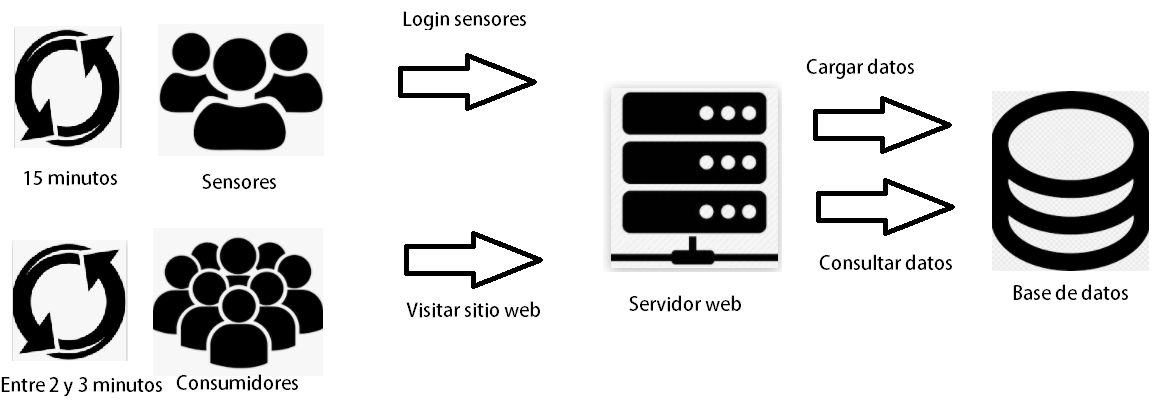
A nivel general, puede decirse que hay dos tipos de usuarios. Sensores y consumidores. El primer grupo tiene un comportamiento muy caracteristico de acuerdo al tipo de dato adquirido y la frecuencia de actualizacion sobre el servidor web. Mientras que el segundo grupo puede ser modelado a partir de las necesidades de consumo de dichos datos.
De esta forma, resulta distinto analizar un escenario donde los sensores estan capturando variables asociadas al clima y los consumidores no tienen apuro en adquirir dichos datos, que aquellos escenarios donde los sensores manipulan variables criticas en tiempo real y existen consumidores realizando consultas practicamente todo el tiempo.
Este trabajo va orienta al primer ejemplo, donde las variables no son criticas y no se necesitan segundo a segundo pero existe un volumen de trafico significativo dada la cantidad de sensores y consumidores.Los datos de los sensores son temperatura, presion y humedad y la frecuencia con la que se cargan en el servidor web corresponde a intervalos regulares de tiempo de 15 min
¿Tiene logica?
Los datos de los sensores no cambiaran significativamente durante intervalos regulares de tiempo inferiores a 15 minutos, por lo tanto no tiene sentido plantear un escenario donde la carga sea inferior a dicho valor. Ademas, esta periodicidad temporal implicaria la utilizacion de la frecuencia mas alta de carga de datos dentro de un rango temporal de 1 hora, por lo que resultaria una prueba critica para el servidor.
En cuanto al comportamiento de los consumidores, se plantea que cada uno de ellos consulta los datos administrados en el sitio web y previamente cargados por los sensores en las bases de datos, en intervalos regulares de tiempo comprendidos entre 2 a 3 minutos, siempre con un valor aleatorio de consulta a consulta.
Al analizar el script encontramos en las primeras lineas la funcion obt_cred:
def obt_cred(nombre_archivo,cant_user):
print("*************************************************")
print(".............Procesando Credenciales.............")
print("*************************************************")
indice = list(range(0, 2 * cant_user - 1, 2))
f = open(nombre_archivo, "r")
List_prep = f.readline().replace("[", "").replace("'", "").replace("(", "").replace(")", "").replace("]","").split(",")
Credenciales = []
for j in indice:
Credenciales.append(((List_prep[j].strip(),List_prep[j + 1].strip())))
return Credenciales
namefile="/mnt/locust/usuarios.txt"
cantidad_usuarios=1000
Esta funcion permite preparar al script locust para generar las credenciales de cada usuario en formato lista mediante tuplas [("usuario","contraseña"),(,)...] que posteriormente usaran las diferentes instancias (" Hilos de Locust "). Como puede apreciarse en la porcion de codigo presentada anteriormente, los diferentes usuarios y contraseñas se encuentran en un archivo de texto que resulta ser argumento de entrada de la funcion, junto con la cantidad de usuarios.
La siguiente funcion resulta de vital importancia, ya que definira la conexion entre el servicio locust e influxdb como base de datos de series temporales para dar persistencia en el tiempo a las metricas.
hostIP_str="172.21.0.4" #ip apuntando a influx
port_str="8086"
username_str="admin"
passw_str="admin"
database_str="influx"
hostname = socket.gethostname()
client = InfluxDBClient(hostIP_str,port_str,username_str,passw_str,database_str)
@events.request_success.add_listener
def individual_success_handle(request_type, name, response_time, response_length, **kwargs):
SUCCESS_TEMPLATE = '[{"measurement": "%s","tags": {"hostname":"%s","requestName": "%s","requestType": "%s","status":"%s"},"time":"%s","fields": {"responseTime": "%s","responseLength":"%s"}}]'
json_string = SUCCESS_TEMPLATE % ("ResponseTable", hostname, name, request_type, "success", datetime.datetime.now(tz=pytz.UTC), response_time, response_length)
client.write_points(json.loads(json_string), time_precision='ms')
@events.request_failure.add_listener
def individual_fail_handle(request_type, name, response_time, response_length, exception, **kwargs):
FAIL_TEMPLATE = '[{"measurement": "%s","tags": {"hostname":"%s","requestName": "%s","requestType": "%s","exception":"%s","status":"%s"},"time":"%s","fields": {"responseTime": "%s","responseLength":"%s"}}]'
json_string = FAIL_TEMPLATE % ("ResponseTable", hostname, name, request_type, exception, "fail", datetime.datetime.now(tz=pytz.UTC), response_time, response_length)
client.write_points(json.loads(json_string), time_precision='ms')
En primer lugar se definen variables como direccion ip y puerto donde se encuentra funcionando Influxdb, asi como tambien nombre de la base de datos, usuario y contraseña para posteriormente crear una conexion e incorporar dos eventos a la escucha.
Estos eventos saltan cuando locust tiene respuesta a las peticiones que generan cada uno de los hilos (usuarios). Ante respuestas exitosas, request_success se hace cargo de generar una escritura en influxdb en la medida "ResponseTable" que tendra como secciones:
De la misma forma ocurre con aquellas respuestas que acusan algun tipo de fallo. En esta situacion, el evento a la escucha que se encargara de la escritura es request_failure
| hostname |
| requestName |
| requestType |
| status |
| time |
| fields responseTime (tiempo de respuesta) , responseLength (Longitud de la respuesta) |
Luego se definen las clases y sus tareas, asi como tambien los tiempos de espera entre ejecucion de tareas de cada hilo y la preferencia de eleccion entre ellas. Todo esto determina el comportamiento de cada hilo o como comunmente definimos nosotros "usuarios". Es posible modelar de forma distinta cada clase haciendo uso puramente y esclusivamente de python, lo que permite hacer una infinidad de modelos y pruebas de rendimiento interesantes.
class UserSensor(HttpUser):
wait_time = constant_pacing (900)
weight = 1
@task
def login_register_logout(self):
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
print("Realizando:__ Login Register Logout__")
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
usuario,contraseña,estado=self.login(Credenciales)
if estado ==1:
self.register_date()
self.logout(usuario,contraseña)
def login(self,Credenciales):
print("______________Proceso de Login_____________")
status=0
if len(Credenciales) > 0:
user,password=Credenciales.pop()
respuesta = self.client.get("/accounts/login/")
if respuesta.status_code==200:
csrftoken = respuesta.cookies['csrftoken']
respuesta_1=self.client.post("/accounts/login/", {'username': user, 'password': password},headers={'X-CSRFToken': csrftoken})
if respuesta_1.status_code==200:
print("____________Exito Login_________________")
status=1
else:
print("____________Falla Login _________________")
Credenciales.append((user, password))
else:
print("____________ Falla Login al ingresar a la pagina_________________")
Credenciales.append((user, password))
else:
print("No hay credencial disponible")
user=""
password=""
return user,password,status
La clase presentada en la seccion de codigo anterior, hereda las caracteristicas de la clase HttpUser, ya que con esta ultima resulta mucho mas simple mantener secciones abiertas para lograr login, post y demas. Se denomina Usersensor y tiene una unica tarea definida como login_register_logout que como su nombre lo indica, tiene como finalidad, generar un registro de un dato por parte de un sensor luego de un login y finalizar con un logout, para liberar la conexion. Luego de finalizar la tarea, el hilo duerme un periodo de tiempo necesario para completar un ciclo de 15 minutos y posteriormente se activa para ejecutar nuevamente la tarea en cuestion. Si los tiempos de ejecucion del hilo superan los 15 minutos y aun no finalizo, se lanza otra instancia, acumulando de esta forma hilos simultaneos.
A pesar de parecer complejo ,el funcionamiento de la tarea es bastante sencillo.
@task
def login_register_logout(self):
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
print("Realizando:__ Login Register Logout__")
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
usuario,contraseña,estado=self.login(Credenciales)
if estado ==1:
self.register_date()
self.logout(usuario,contraseña)
Primero se muestra un mensaje por consola para tener conocimiento que se esta ejecutando la tarea. Luego se ejecuta la funcion login a partir de la instancia actual, pasando como argumento la lista con tuplas que contienen usuario y contraseña disponibles para dicha instancia. Independientemente del resultado del proceso (exito o falla), la funcion devuelve tres variables en una forma u otra. El usuario y contraseña que lograron acceder al servidor web como string y el estado de la conexion en uno, en el caso de ser exitoso y el usuario y contraseña como string vacios junto con estado cero si fallo.
La variable estado es fundamental porque dependiendo su valor, se determinara si se ejecutaran las demas funciones o si el hilo finaliza alli.
La variable estado es fundamental porque dependiendo su valor, se determinara si se ejecutaran las demas funciones o si el hilo finaliza alli.
Como puede observase, la tarea esta compuesta de tres funciones: login,register_date y logout. La primera de ellas ya fue presentada, lo que nos lleva a la funcion register_date
def register_date(self):
print("_________Subiendo Datos_________")
ubc_var = ['RC', 'SAM', 'GD']
ubc_selec = random.randint(0, 2)
dat_var_num = [random.randint(-10, 50-1), random.randint(880, 1080-1), random.randint(0, 100-1)]
csftoken=self.client.get("/registro/ingresar").cookies['csrftoken']
posteo=self.client.post("/registro/privado", {'ubicacion':ubc_var[ubc_selec],'temperatura':dat_var_num[0],'presion':dat_var_num[1],'humedad':dat_var_num[2]},headers={'X-CSRFToken': csftoken})
if (posteo.status_code == 200):
print("_______Exito en la subida de datos ____________")
else:
print("_____________Fallo el registro de datos______________")
Esta funcion, genera un vector con las tres variables a cargar en la base de datos, generadas de forma a aleatoria en los rangos (-10,49) para temperatura, (880,1079) para presion,(0,99) para humedad. Posteriormente , selecciona una ubicacion al azar entre RC, SAM y GD y arma la solicitud para realizar un POST. Por ultimo la funcion Logout se asegura de finalizar la conexion del usuario y devolver las credenciales utilizadas para que otro proceso pueda volver a tomarlas.
def logout(self,user,password):
print("______________Proceso de Logout____________")
respuesta=self.client.get("/accounts/logout/")
while (respuesta.status_code != 200):
print(" __________Intentando nuevamente logout________ ")
respuesta = self.client.get("/accounts/logout/")
print("-----------------Logout exitoso---------------")
Credenciales.append((user, password))
La segunda clase denominada UserCons tiene dos tareas definidas como consultaindex y consultabasedatos. La primera tarea solamente realiza un GET al index de la pagina web y la segunda realiza un POST para consultar datos. Ambas tienen igual probabilidad de ejecutarse al crearse un nuevo hilo.
class UserCons(HttpUser):
wait_time = between(120,360)
weight = 3
@task
def consultaindex(self):
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
print("Realizando:__consultaIndex__")
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
self.client.get("/")
@task
def consultabasedatos(self):
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
print("Realizando:__Consulta Base de Datos__")
print("-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_-_")
ubc_var = ['RC', 'SAM', 'GD']
list_ubic=[]
ubc_cant=random.randint(1,3)
ubc = random.randint(0, 2)
if ubc_cant == 1:
list_ubic.append(ubc_var[ubc])
elif ubc_cant == 2:
list_ubic.append(ubc_var[ubc])
ubc1=random.randint(0,2)
while (ubc1 == ubc ):
ubc1=random.randint(0, 2)
list_ubic.append(ubc_var[ubc1])
else:
list_ubic=ubc_var
dat_var = ['TEMP', 'PRE', 'HUM']
list_dato=[]
dat_cant=random.randint(1,3)
dat = random.randint(0, 2)
if dat_cant == 1:
list_dato.append(dat_var[dat])
elif dat_cant == 2:
list_dato.append(dat_var[dat])
dat1=random.randint(0,2)
while (dat1 == dat ):
dat1=random.randint(0, 2)
list_dato.append(dat_var[dat1])
else:
list_dato=dat_var
cookies=self.client.get("/registro/procUser").cookies['csrftoken']
self.client.post("/registro/procUser",{'SelecUbic':list_ubic,'SelecDato':list_dato},headers={'X-CSRFToken':cookies})
La ultima tarea presentada parece ser algo compleja pero solamente esta construyendo una consulta al servidor web mediante metodo POST teniendo como referencia el formato de formulario presentado por django. Para que la solicitud sea considerada valida debe tener al menos un elemento identificable tanto en SelecUbic como en SelecDato dentro del set de posibilidades y debe ser presentado en formato lista. Entiendase un vector para SelecUbic con uno o mas valores dentro de las posibilidades (RC,SAM,GD) y lo mismo para SelecDato pero con valores como (TEMP,PRE,HUM ). El codigo tiene un poco mas de logica porque la construccion parte de procesos aleatorios. Estos ultimos, permiten que cada solictud sea diferente a la anterior, permitiendo generar diferentes cargas de trafico, ya que no seria lo mismo solicitar unicamente la temperatura de sampacho que pedir temperatura, presion y humedad tanto para rio cuarto, sampacho y general deheza. De esta manera, se generan un avanico de posibles solicitudes dadas la cantidad de valores diferentes que tiene cada variable y todas las posibles combinaciones que pueden ser generadas.